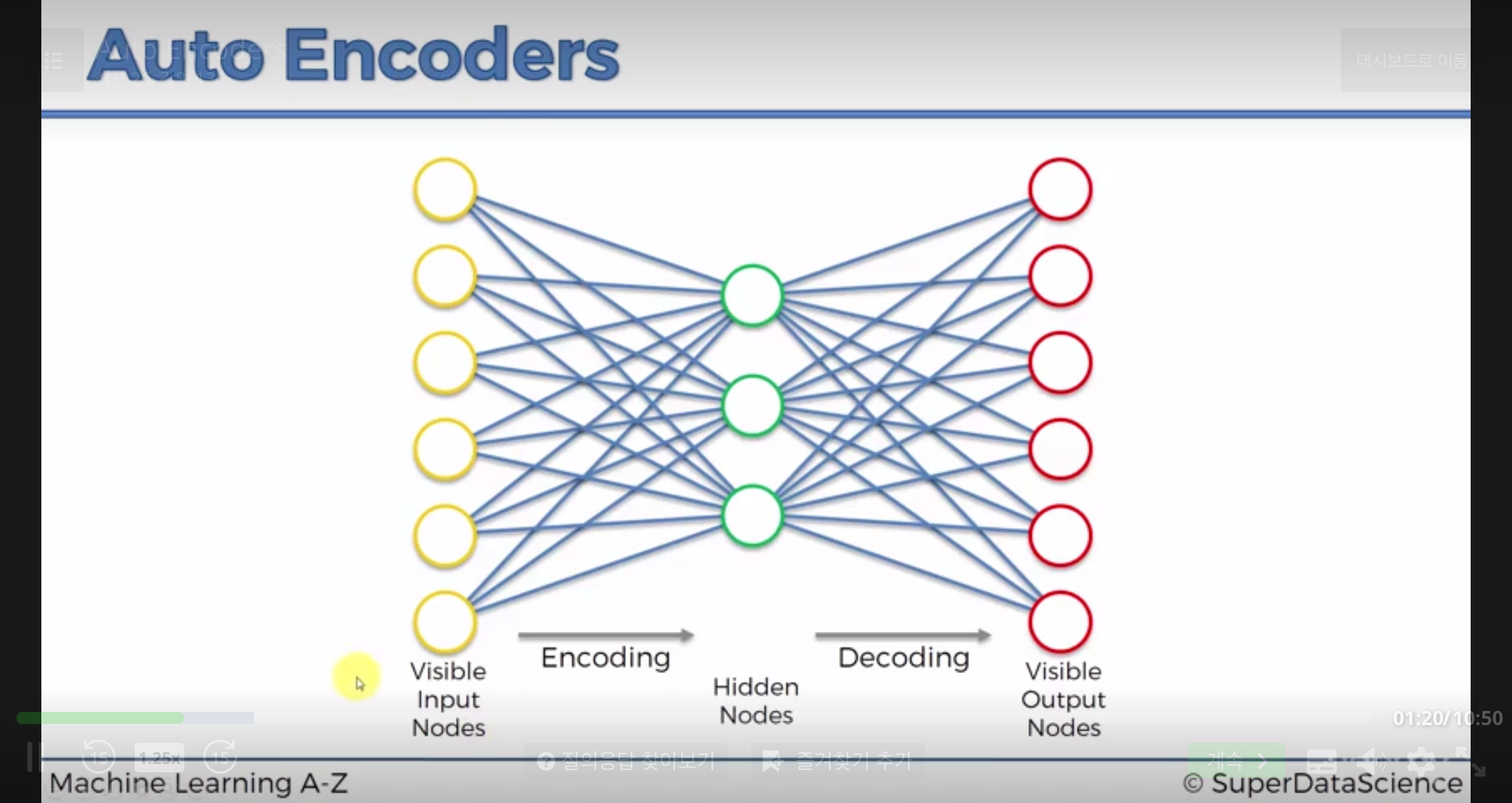
Autoencoder 의 간략한 구조는 위와 같다.
=> self supervised learning 에 가깝다.
자기 자신을 target(label) 값으로 사용하기 때문이다.
가운데 초록색 노드들(Hidden nodes) 을 coding layer, 또는 bottleneck 이라고 부른다.
1. Autoencoder 를 어디에 쓰나
**1.feature detection **
학습된 autoencoder에서는 coding layer 가 input 의 중요한 feature 들을 나타내게된다.
2.recommendation system
추후 튜토리얼을 확인하자.
**3.encoding **
Decoder로 디코딩할수 있는 코드로 input 값을 encoding(암호화) 하는 기능을 할 수 있다.
2. Autoencoder 의 작동
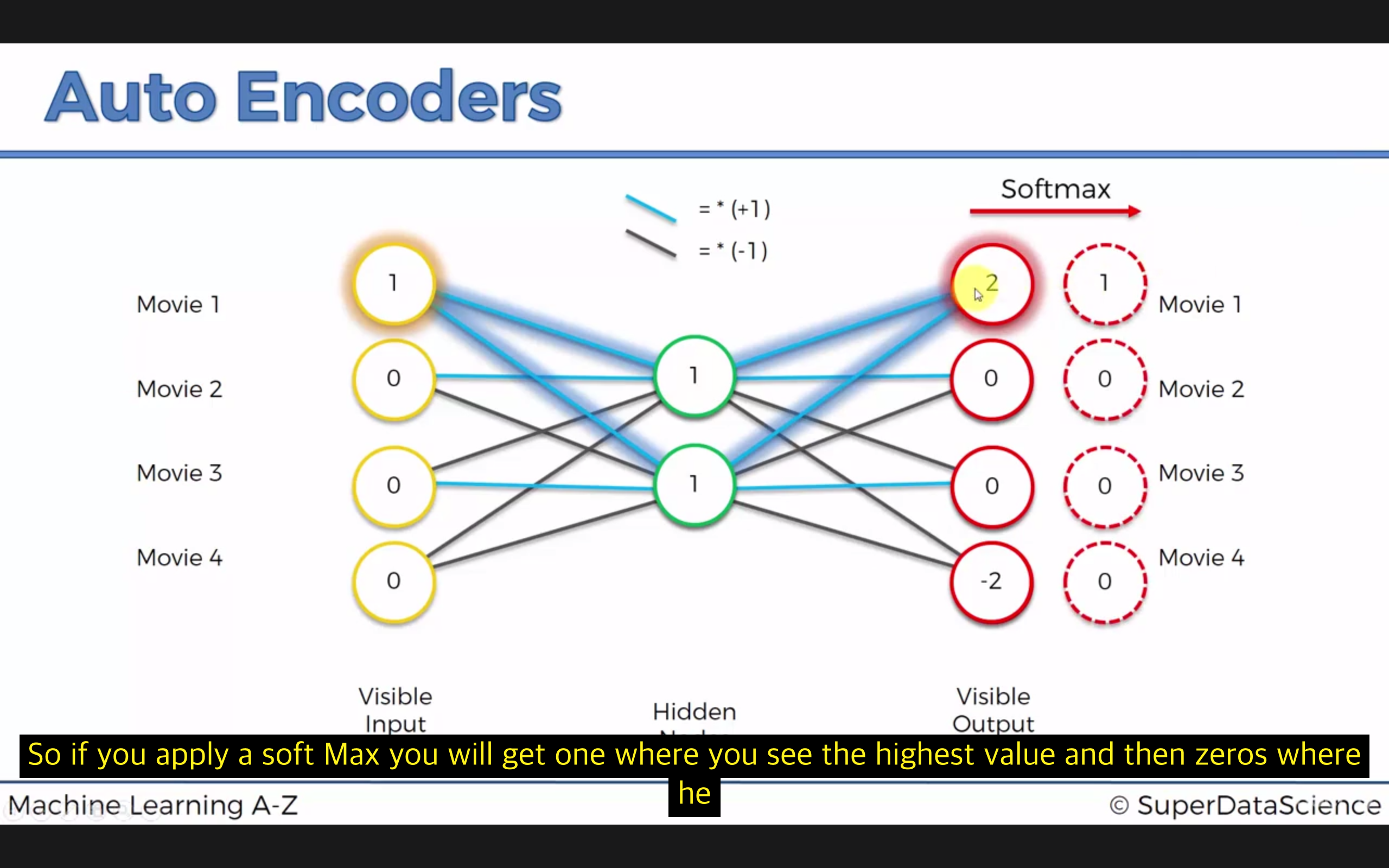
이 사이트 를 참고한 모델을 설명한다.
주로 activation function 으로 tanh 를 사용한다. (hidden 직전과 visible 직전에)
output 값에 softmax 를 사용한다.
3. Autoencoder 의 Bias
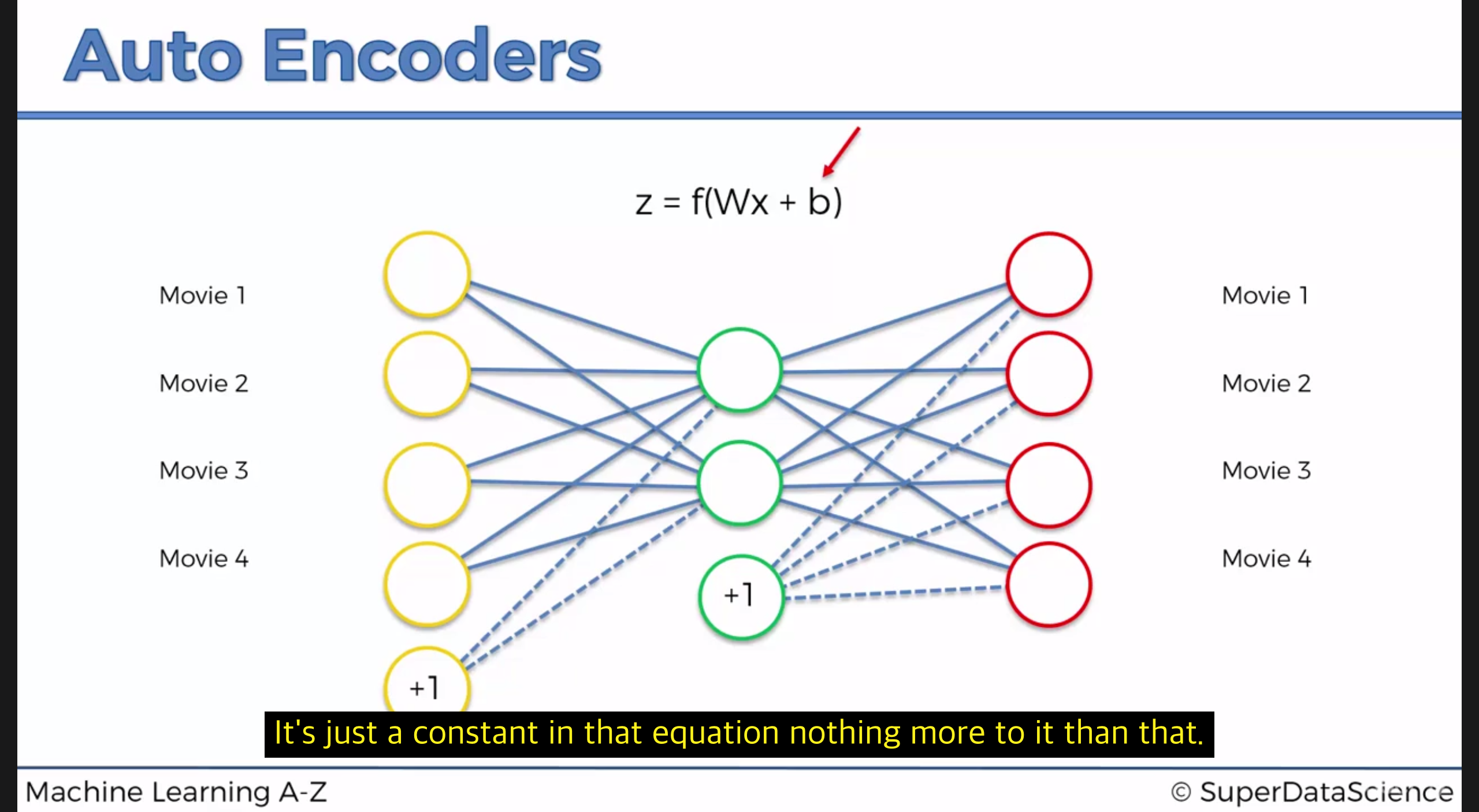
이렇게 Bias 를 추가할 수도 있고, 그림으론 이렇게 표현한다.
4. Autoencoder 의 Training
| step | 내용 | 부가 |
|---|---|---|
| 1 | input vector x_u = (r1,r2,.., ri,…,rm) 은 user u 의 m개의 영화에 대한 rating이다. | rating은 1~5 사이의 값이고, rating 없으면 0이다. |
| 2 | input vector(user 단위) 가 하나 network 로 들어간다. | |
| 3 | input vector x_u 는 vector z 로 인코딩된다.x 에서 z 로 갈 때 mapping function 에 의해 차원이 축소된다. | mapping function : z = f(Wx+b) (f : sigmoid, tanh , etc) |
| 4 | z 가 output vector y로 decoding 된다. y는 x vector 와 같은 차원을 가진다. | y가 x의 복사본이 되게 하는 것이 학습의 목적이다. |
| 5 | reconstruction error d(x,y) 를 계산한다. 이 error function 을 최소화시킨다. | error function : d(x,y)=//x-y// |
| 6 | back-propagation 을 이용해, error 의 값이 역전파되고, W,b 값들이 tuning 된다. | learning rate 에 따라 학습 정도가 달라진다. |
| 7 | step 1~6 을 반복하면서 파라메터들을 업데이트한다. | 만약 vector 하나씩 넣으면서 update 시키면 Reinforcement Learning 이고, 여러 batch 씩 한꺼번에 넣으면서 학습시키면 Batch Learning |
| 8 | 전체 데이터셋을 한번 다 학습시켰다면, epoch 단위로 몇번 더 학습한다. |
5. Hidden Layer 의 갯수가 많을수록 좋을까?
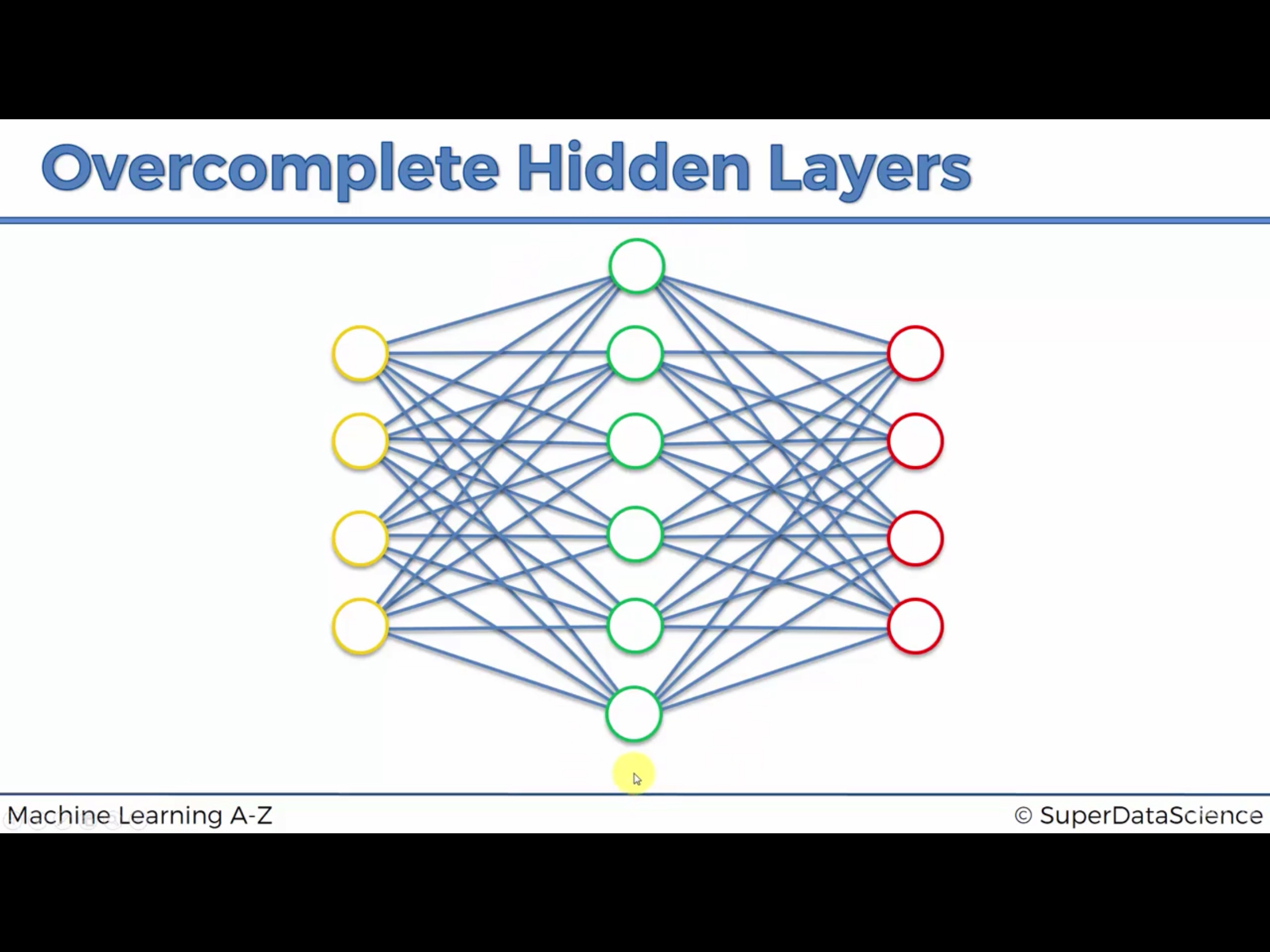
위와같이 hidden node 의 갯수를 input 갯수보다 늘리면 좋을까?
언뜻 생각하면, 더 많은 feature를 뽑아낼 수 있어서 좋겠다 라고 생각할 수 있지만 실제론 그렇지 않다.
맨 상단과 맨 아래 있는 node 가 사용되지 않고, 가운데 5개의 node 가 input 을 output 으로 그대로 복사하는 문제가 생긴다.
encoding 의 기능이 없어지는 것이다. 그렇게되면 의미있는 feature 를 뽑아낼 수 없다.
이러한 문제, 즉 Autoencoder 의 Overfitting(과적합) 문제를 해결하기 위한 Regularization 방법들을 소개한다.
Sparse AE,
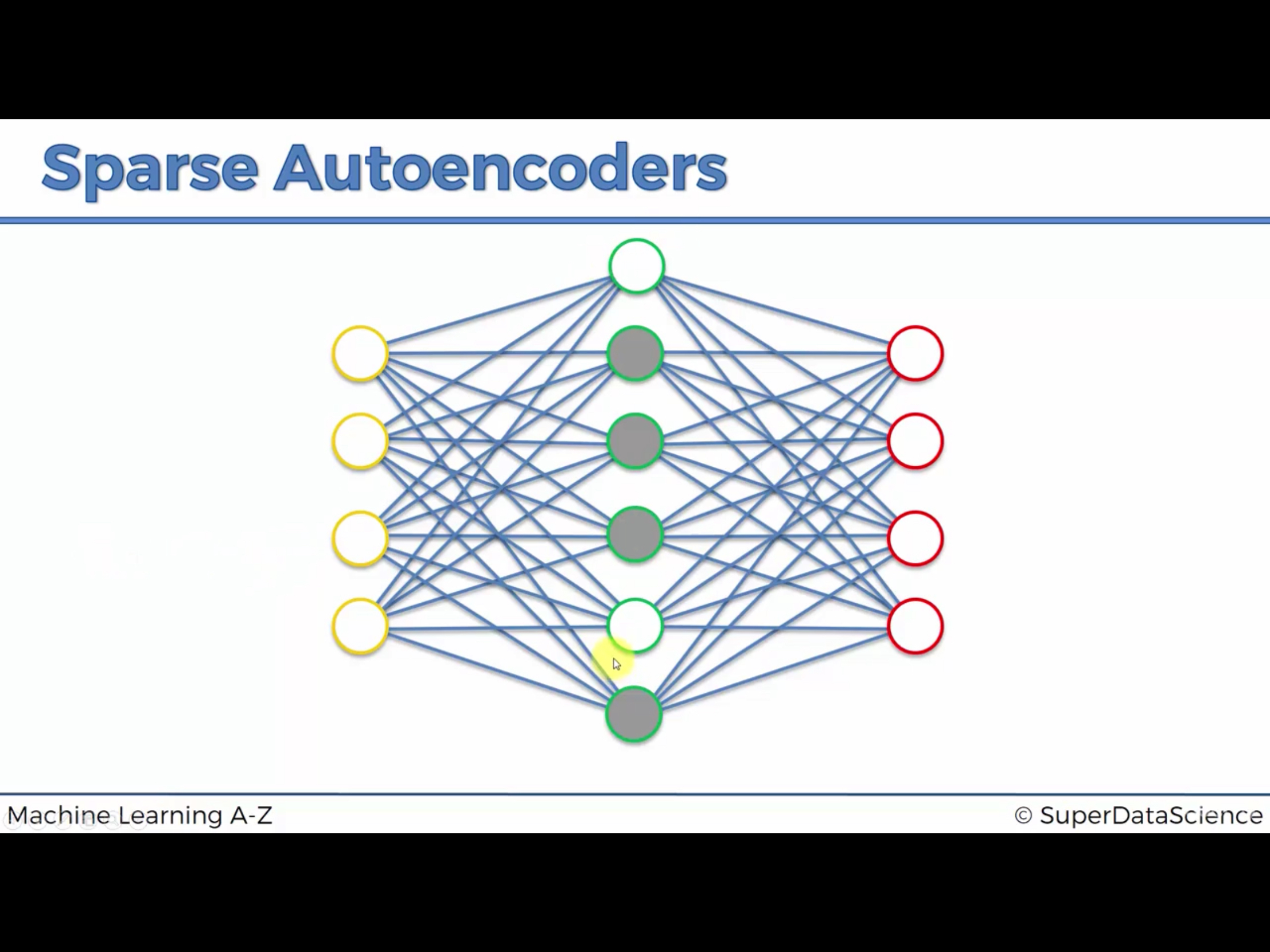
6. Regularization1 : Sparse Autoencoder
매우 유명하다. 굉장히 많이 사용된다.
위처럼 데이터를 그대로 옮기는 hidden node 가 생기는 overfitting 문제를 해결한다.
간단히 말하자면 hidden node 중 매번 일부 node 만 사용해서 학습한다.
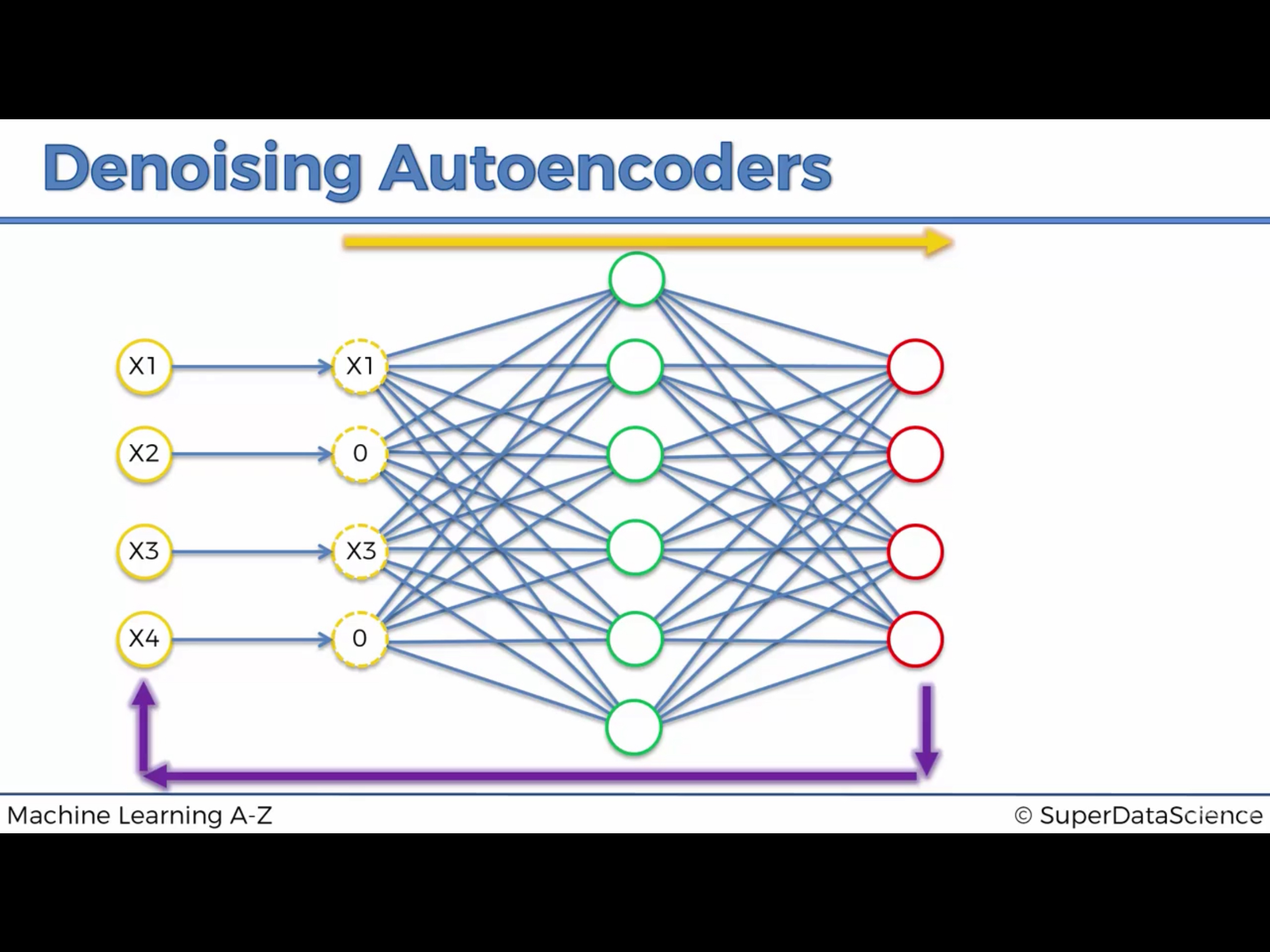
7. Regularization2 : Denoising Autoencoder
Stochastic 한 Auto Encoder 다.
input X 중의 일부만 사용한다.
8. Regularization3 : Contractive Autoencoder
정리 후 내용을 추후 추가하겠다.
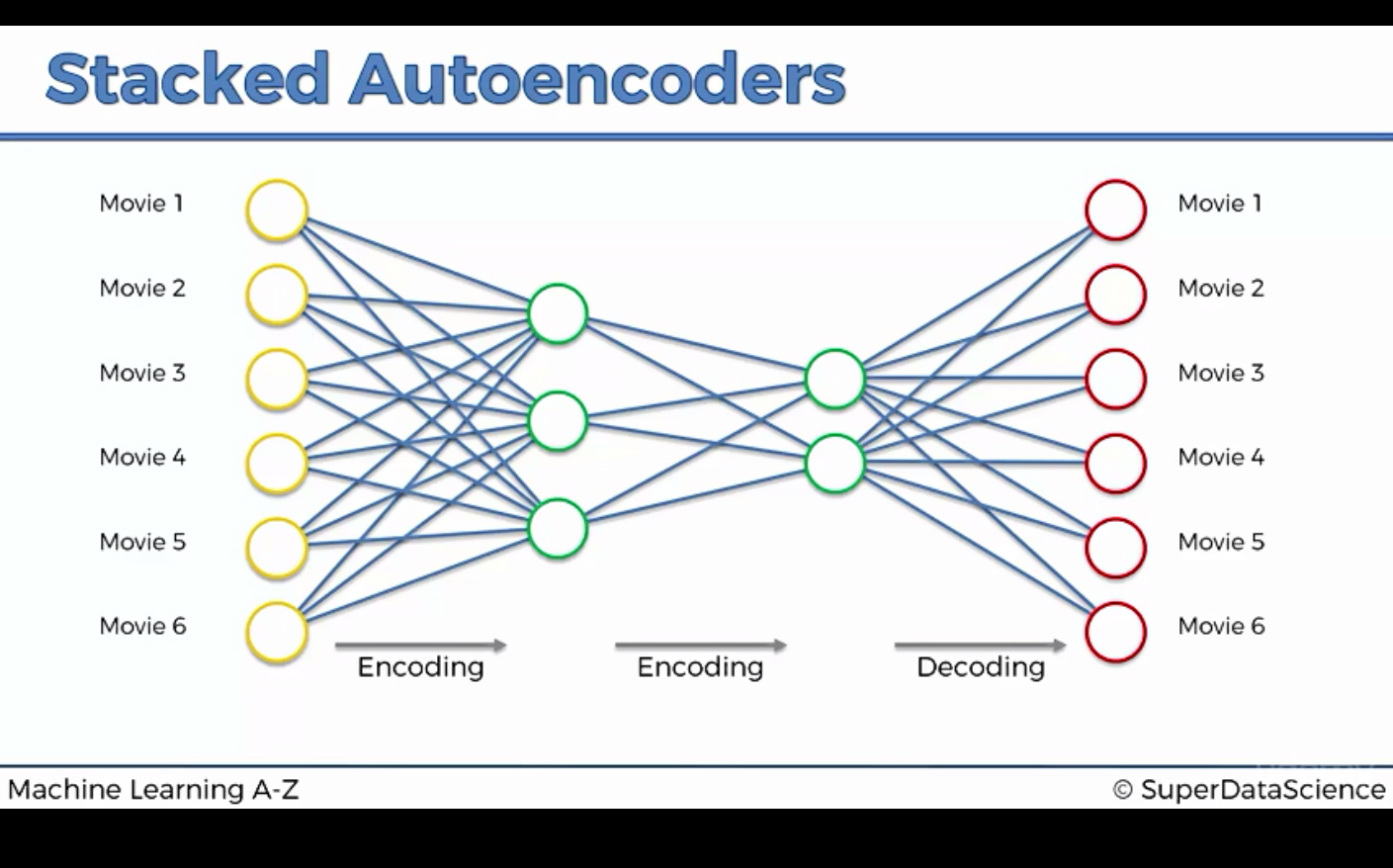
9. Stacked Autoencoder
Stacked Autoencoder 는 간단히 encoding layer를 하나 더 추가한 것인데, 성능은 매우 강력하다.
이 간단한 모델이 Deep Belief Network 의 성능을 넘어서는 경우도 있다고 하니, 정말 대단하다.
참고자료를 읽고, 다시 정리하겠다.
10. Deep Autoencoder
Deep autoencoder 를 알기 전에 확실하게 짚고 넘어가야할 부분은, **Deep Autoencoder 와 Stacked Autoencoder 는 전혀 다른것이다. **
반드시 구분해야한다.
Deep autoencoder 는 RBM ( Ristricted Boltzman Machine ) 을 쌓아 만들었고,
Stacked autoencoder 는 autoencoder 의 encoding layer 를 깊게 쌓아 만든 것이다.