이번 글에서는 Textboxes: A Fast Text Detector with a single Deep Neural Network(2016) 란 딥러닝 최신 논문을
가볍게 정리해보도록 하겠습니다.
참고 링크
1. Introduction
scene text detection 의 효용성
scene text 가 일상 환경에서 많이 접할 수 있는 visual object 이며, scene text detection 의 일상에서의
높은 효용성을 강조합니다.
scene text detection 발전의 어려움
기존의 traditional OCR(전통적인 광학적 문자인식)과 매우 유사한 task를 가지고 있음에도 불구하고,
scene text detection 은 많은 어려움으로 더딘 발전을 겪고 있었다고 합니다.
그 어려움에는 ‘너무 다양한 배경과 글자의 형태’ , ‘빛 상태에 따른 글자 상태의 다양성’ 등이 있습니다.
기존의 복잡하고 느린 scene text detection 모델
기존의 scene text detection 은
“글자/단어 후보 생성” -> “후보 필터링” -> “grouping” 과 같은 여러 단계로 나누어져 있어서,
모델 학습 중의 tuning 이 매우 어려웠고,
완성된 모델의 속도도 매우 느려서 real-time detection 에 적용하기 힘들었다고 합니다.
한계를 극복한 textboxes
저자는 Textboxes 는 object detection 에서 큰 성능 향상을 보여준 SSD(2015) 논문 을 본따 만들었으며,
single network 로 구성되어있기 때문에 기존의 모델들에 비해 현저히 빠른 성능을 보여주고,
정확도 또한 기존 모델들로부터 크게 향상시켰다고 말합니다.
SSD 와의 유사성
Textboxes 모델은 SSD(sigle shot mulitbox detector) 와 구조가 매우 유사하며,
오직 모델 내부의 몇가지 하이퍼-파라메터들만 텍스트 인식에 알맞도록 조정하였다고 합니다.
( default box 와 convolutional kernel(filter) 의 종횡비(ratio) 를 가로로 길게 늘린 것이 그것입니다 )
word recognition 의 feedback 을 통해 detection 성능을 더욱 향상 가능
보통 scene text reading 분야는 text detection 과 text recognition 의 두가지 task로 나뉘는데
Textboxes 모델은 이중에 text detection 을 수행합니다.
하지만 Textboxes 는 detection 후 다양한 text recognition 모델들과 연계가 가능하며,
특정한 given set (lexicon, 단어무리) 이 주어졌을 때에는 text recognition 의 feedback이 detection 모델의 학습 성능을 향상시켜준다고
논문에서는 말합니다.
2. Related Works
선행 논문
scene text reading 분야는 detection 과 recognition 으로 나뉘고,
detection 은 다시한번 charicter based(글자 단위) 와 word based(단어 단위) 로 나뉩니다.
1. charicter based(글자 단위) 선행 논문
Lukas Neumann, Jiri Matas 의 real time scene textlocalization and recognition(2012)
2. word based(단어 단위) 선행 논문
< R-CNN based >
Max Jaderberg, Karen Simonyan, Andrea Vedaldi, Andrew Zisserman 의 Reading Text in the Wild with Convolutional Neural Networks(2015)
< YOLO based >
Ankush Gupta, Andrea Vedaldi, Andrew Zisserman 의 Synthetic Data for Text Localisation in Natural Images(2016)
Textboxes 는 word based 모델
Textboxes 는 단어별로 detection 하는 word based 모델입니다.
Textboxes 는 SSD 에서 영감
Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, Alexander C. Berg 의
Textboxes 의 모델 구조는 SSD(Single shot mulitbox detector) 에서 영감을 얻었습니다.
( 실제로 SSD 에서 사용하는 모델 구조, box matching scheme , loss function 등을 인용해 거의 그대로 사용합니다.)
Textboxes( detection ) -> CRNN( recognition ) 의 연결도 구현함
Shi, Baoguang; Bai, Xiang; Yao, Cong 의 An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition(2015)
end-to-end(detection to recognition) 모델 학습을 위해 Textboxes 모델과 CRNN 을 통한 text recognition 모델을 연결하여 사용하였습니다.
논문은 뒷단에 다양한 recognition 모델을 붙여 end-to-end training 이 가능한 것이 Textboxes 의 장점이라고 밝혔습니다.
3. Detecting with Textboxes
3-1. Training Phase
모델 구조 Architecture
Textboxes 는 오직 convolution과 pooling 으로만 이루어진 fully-convolutional-network 입니다.
<논문의 모델="" 그림="">
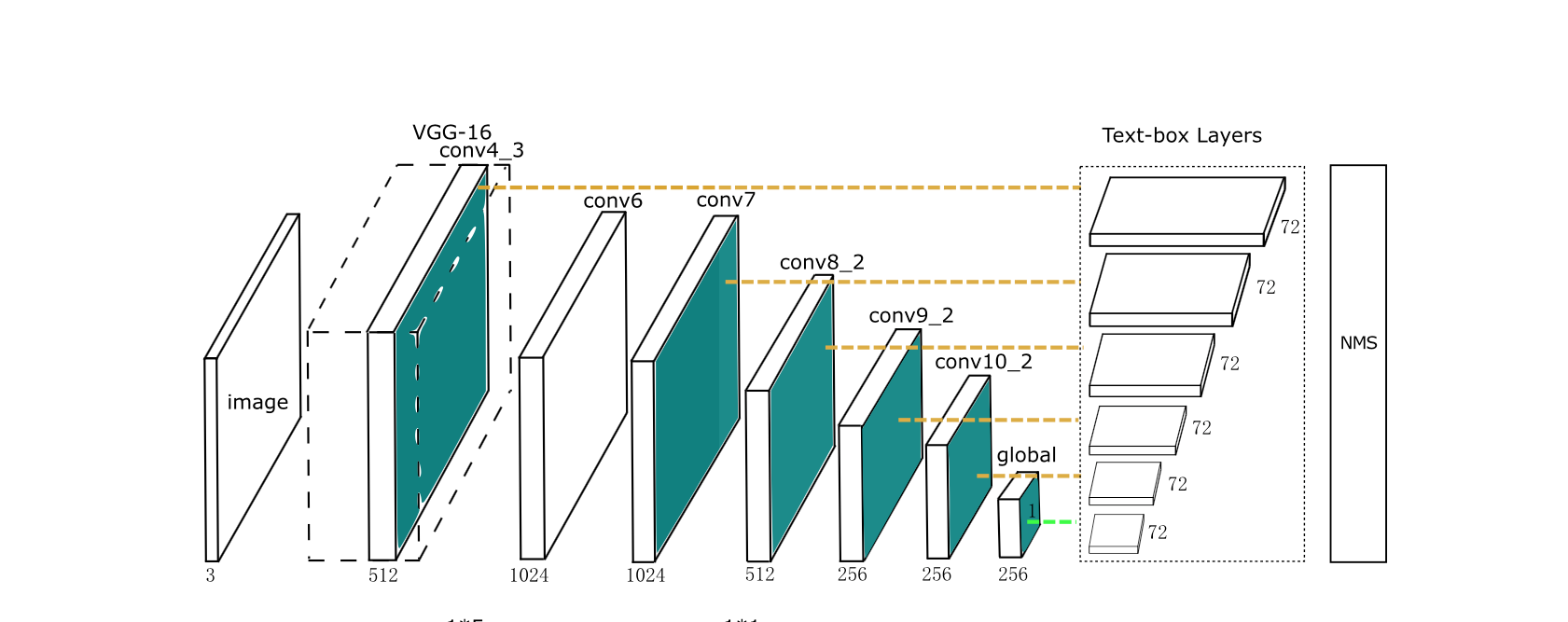
위는 논문에 실린 모델의 모습입니다. 이 모델 그림을 기반으로 아래에 제가 해석한 모델 그림을 그려보았습니다.
<직접 다시="" 그린="" 모델="" 그림="">
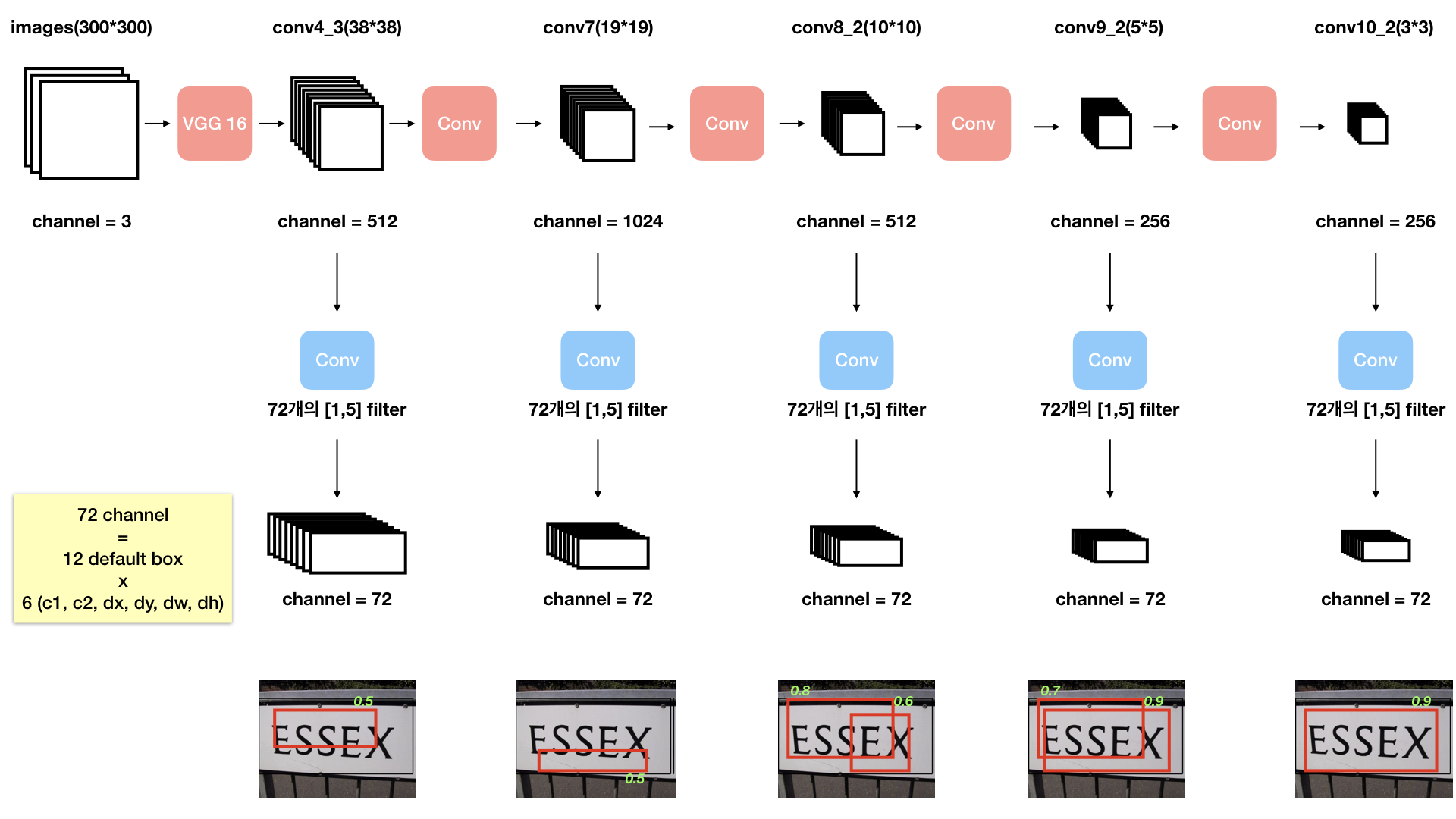

input images 는 RGB 로 3개의 채널로 되어있습니다.
input images 의 사이즈는 임의로 300*300 으로 설정하고 진행하였습니다. (다른 사이즈의 input 도 가능합니다)
<용어>
연속적인 convolution layer 가 이어진 부분을 “Base network” 이라고 하고,
Base network 에서 중간중간 feature map 을 가져오는 위치를 “Map Point” 라고 일컫습니다.
Map Point 에서 가져온 feature map 들을 새로운 convolution 을 수행해서 만들어낸 이 모델의 output 들을 “Textbox Layer” 라고 부릅니다.
즉 Textboxes 모델은 training (loss function) 에 사용되는 output 이 한 값이 아닌, Textbox Layer 가 됩니다.
input images 는 Base network 을 거치면서 수많은 feature map들을 만들고,
중간중간 Map point 에서 feature map 들을 추출해 가로로 긴 filter([1,5]) 를 이용한 convolution 을 수행해
channel 이 72개인 Texbox Layer( output ) 를 생성해냅니다.
다양한 크기의 feature map 을 중간중간 이용하는 이유는 다양한 크기의 text 들을 detection 하기 위해서입니다.
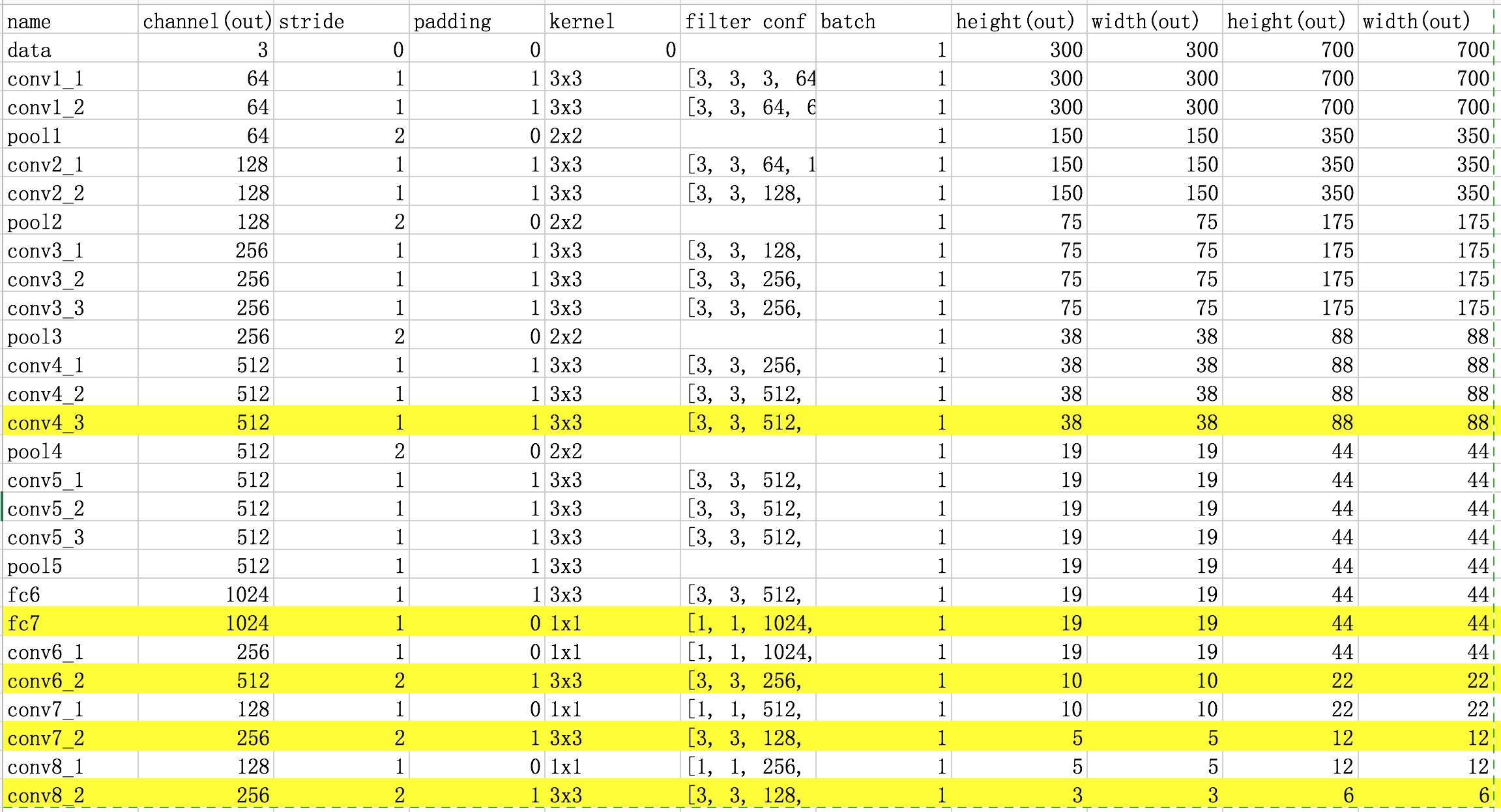
Base network 내부 데이터 흐름 표
표에서 노란색으로 하이라이트 된 부분이 Map Point 입니다.
Textbox Layer 의 채널이 72개인 이유
72 라는 숫자는 무엇일까요?
Textboxes 모델은 각 Map Point 의 각 픽셀마다 Default Box 를 다양한 종횡비로 12개씩 미리 설정해놓습니다. (SSD 와 같습니다)
(무수히 많은 default box 들이 생깁니다.)
하나의 Default box 는 하나의 predicted box 를 만들어냅니다.
predicted box는 offset 4값(dx, dy, dw, dh) 과 confidence 2값(c1, c2) 으로 이루어져 있습니다.
하나의 feature map 픽셀당 12개씩의 default box들이 존재하므로
총 12 * 6(4+2) = 72 개의 결과값이 나옵니다.
offset?
predicted box 가 산출된 defualt box 로부터의 형태 변화량입니다.
하나의 default box는 하나의 predicted box 를 만들어낼 때
한 default box 가 (x0,y0) 에 위치하고 **너비가 w0, 높이가 h0 ** 라고 하면
(모든 box들은 0~1 로 scaling 된 맵 위의 (x,y,w,h) 값을 가집니다. 그래야 서로 다른 크기의 map location 들사이에서의 비교가 가능하기 때문입니다. )
그리고 그 default box로부터 예측된 predicted box 의 offset 이 (dx, dy ,dw, dh) 라면
predicted box 의 위치 정보(x, y, w, h)는 다음과 같이 복구할 수 있습니다.
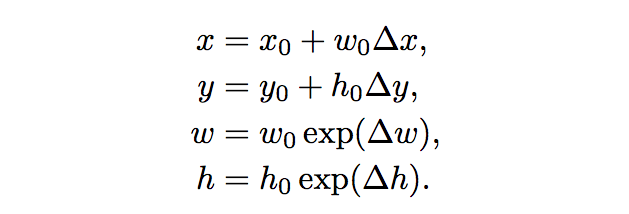
Default box 를 만드는 방법
모델을 훈련시키기 전, 우선 각 Map Location 의 각 픽셀당 12개씩 , 총 수만개의 Default box 들을 만들어주어야 합니다.
각 default box의 x0,y0 값(0~1 사이로 scaling된 값) 은 각 Map Location 의 각 픽셀마다 모두 다르지만
w0,h0 값은 아닙니다.
종횡비(ratio) 와 Scale 이라는 값으로 컨트롤합니다.
한 Map Location 의 12개의 Default Box들은 각 픽셀마다 모양이 모두 같다.
12개의 종횡비(ratio)를 미리 설정해놓기 때문이다. (w:h)
하지만 각 Map Location 마다 Default Box의 (w0,h0) 들은 각각 다르다.
6개의 Map Location 마다 정해진 종횡비에 특정 Scale 을 곱해서 w0, h0 를 구성하기 때문이다.
1) 종횡비 구성
텍스트는 기본적으로 옆으로 긴 형태를 띄고 있기 때문에 Default box 의 종횡비 또한 가로로 깁니다.
논문에서는 종횡비 6가지 (1,2,3,5,7,10) 을 설정해서 픽셀의 중심에 한번, 픽셀의 아래에 한번 적용해
총 12개를 한 픽셀의 default box로 정합니다.
중심에 모든 박스를 넣지 않고 살짝 아래로 6개를 내린 이유는 촘촘한 detection 을 위해서입니다.
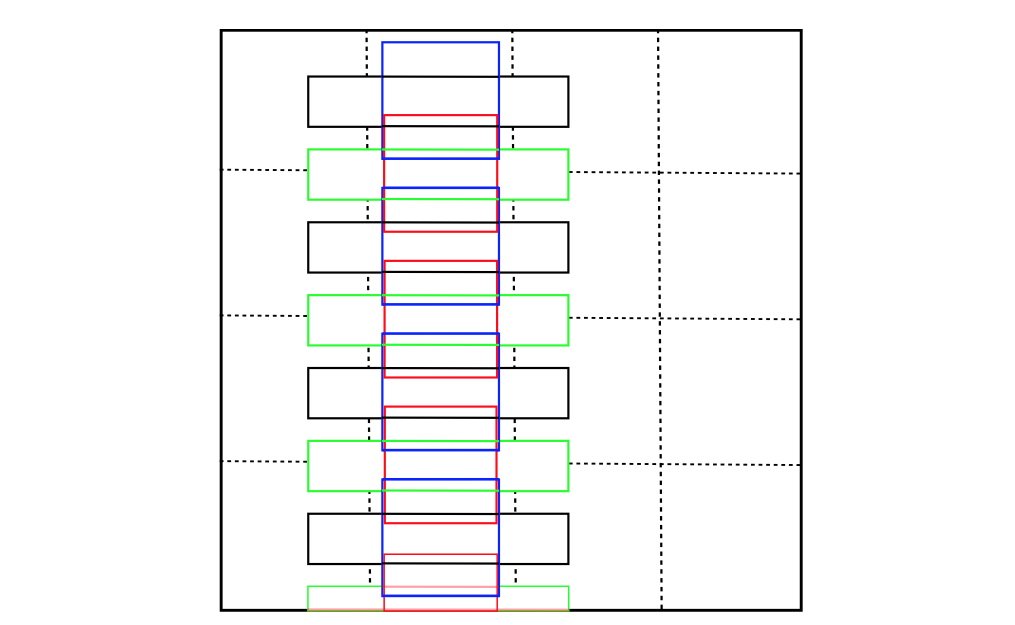
그림에서 파란색은 (중심, 종횡비 1) , 검은색은 (중심, 종횡비 5), 빨간색은 (아래, 종횡비 1), 초록색은 (아래, 종횡비 5) 입니다.
2) Scale 구성
Scale 에 관한 내용은 본 논문에는 나와있지 않지만 SSD 논문에 기술되어있고, 실제로 Textboxes 구현에서도 사용됩니다.
6개의 Map location 의 각 Scale 들은 등차수열을 이룹니다.
Loss Function
이렇게 모든 default box 들을 준비하고, Network Model 까지 준비한 후
이 모델에 image 를 넣고 동작시키면
수만개의 default box 들에서 각각 (dx, dy, dw, dh, c1, c2) 값이 산출됩니다.
이 값들은 loss function 을 구성하는 데에 쓰이고,
우린 Optimizer 를 통해 이 loss function 을 최소화 시키는 방향으로 매 iteration 마다 나아갈 것이고,
이 과정을 무수히 많이 반복하게 됩니다.
loss function 의 수식은 아래와 같습니다.
간단히 요약하자면
total loss = confidnece loss + location loss
입니다.
confidence loss 에는 softmax loss 함수를 사용합니다.
location loss 에는 smooth_L1 loss 함수를 사용합니다.
(아래 수식은 SSD 논문에서 가져왔습니다.)

그런데 중요한 것은 우리가 모든 default box 에서 나온 prediction 값을 사용하지 않는다는 것입니다.
**default box 들을 positive 와 negative 로 분류합니다. **
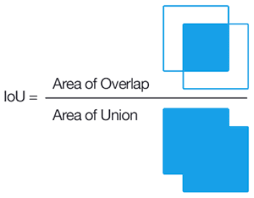
Jaccard Overlap & Hard Negative Mining
우리가 미리 만들어놓은 모든 default box 들과 한 이미지의 모든 ground truth box 들의 Jaccard Overlap 을 비교하여
Jaccard Overlap > 0.5 이상인 dafualt box 들을 positive
Jaccard Over < 0.5 이하인 default box 들을 negative 라고 지정합니다.
이렇게 나누면 negative 의 갯수가 positive 의 갯수보다 현저히 많기 때문에
negative 의 갯수가 positive 의 갯수의 3배가 되도록 negative 일부를 무시하고 날립니다.
이 과정을 Hard Negative Mining 이라고 합니다.
Jaccard Overlap 논문내용 (SSD)

Hard Negative Mining 논문 내용(SSD)

분류가 끝나면, default box들 중
**location loss 에서는 positive box 들만을 사용하고 **
**confidence loss 에서는 positive box 들에서는 c1 을 사용하고 negative box 들에서는 c2 를 사용합니다. **
total loss 는 (location loss + confidence loss)/N 이 됩니다.
N 은 positive 로 검출된 box의 갯수입니다.
이 값을 Optimizer 를 통해 줄여나가면서 모델을 학습시키면 됩니다.
3-2. Validation/Test Phase
Non Maximum Supression (NMS)
Training 이 끝난 모델에 input image 를 넣으면 output 으로 Textbox Layer 가 나옵니다.
하지만 Textbox Layer 자체로는 Detecting 완성되었다고 할 수 없습니다.
수많은 값들 중 무엇이 진짜 Predicted Box 인지 골라주어야 합니다.
이 부분에 NMS 라는 방법이 사용됩니다.
참고 링크 : Non-Maximum Suppression for Object Detection in Python
NMS 를 수행하면 위처럼 여러개의 후보 predicted box 를 단일의 Most predicted box로 추려줍니다.
Model Accuracy 측정
학습을 마친 모델의 성능을 보려면 어떻게 Accuracy 를 측정할 것인지도 매우 중요합니다.
Accuracy 측정에는 F-Mesure 를 이용합니다.
F-Mesure
F measure 는 실제로 정확도를 측정하는데 매우 자주 이용되고, 중요합니다.
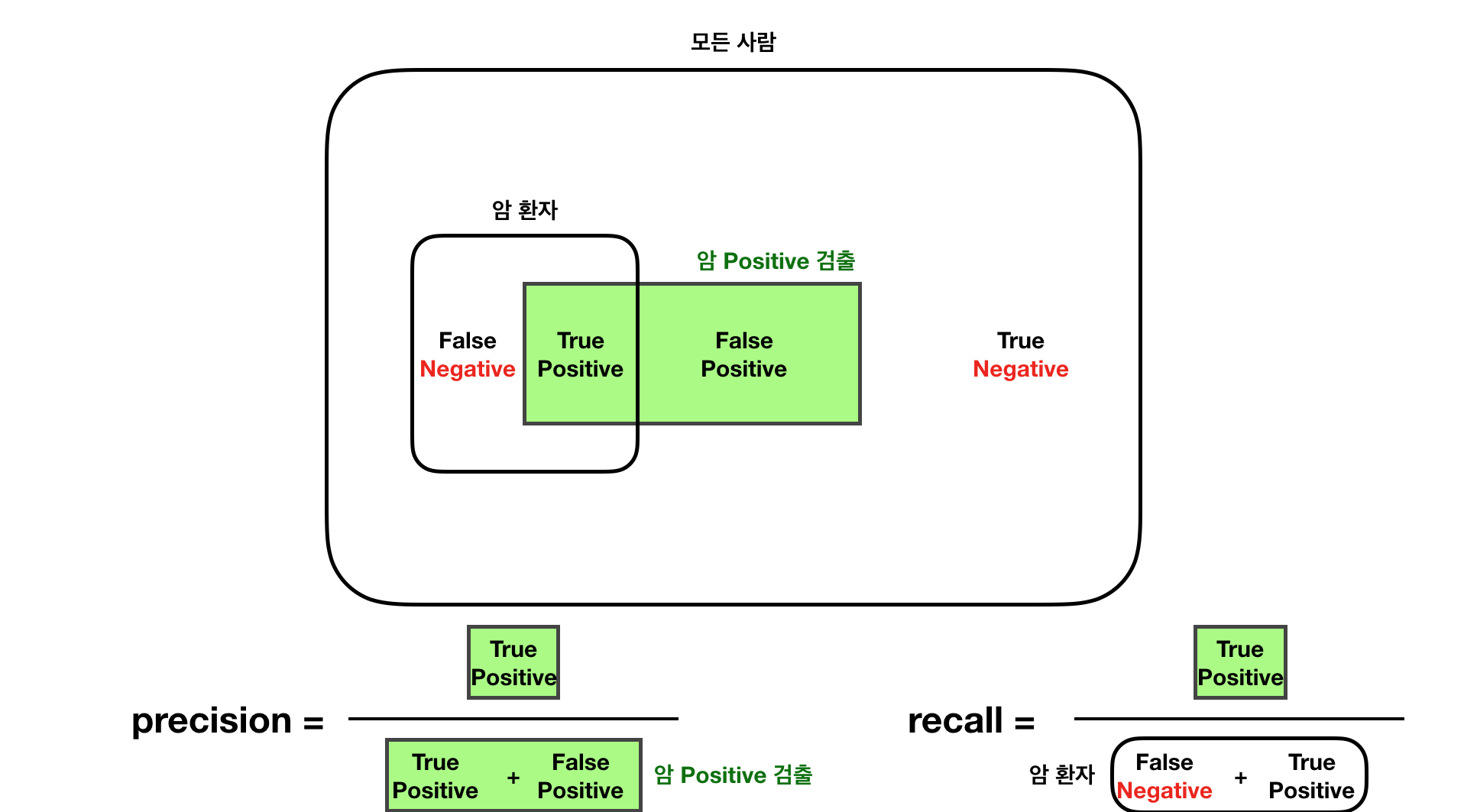
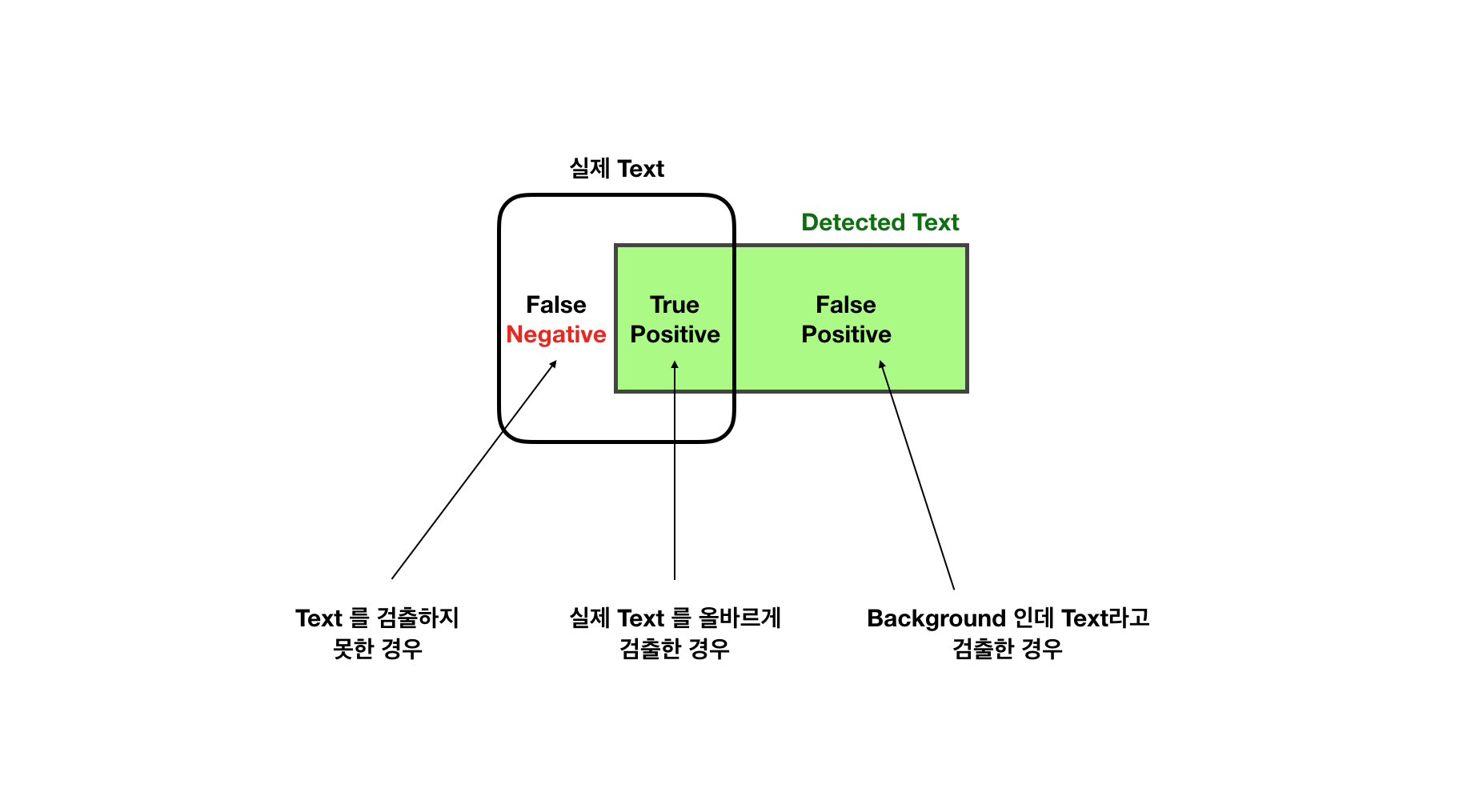
기계학습에서 정확도를 평가하는데 중요한 지표중 두가지가 정확도(precision) 와 재현율(recall) 입니다.
정확도와 재현율에 대한 이해를 돕고자 그림을 그려보았습니다.
정확도(precision)는 우리가 Positive 라고 예상한 것 중 맞춘 것의 비율입니다.
재현율(recall)은 실제 ground truth 중 맞춘 것 의 비율입니다.
이 두 지표 모두 중요한데
F-Mesure 는 precision 과 recall 의 비중을 적절히 혼합한 정확도 수치라고 할 수 있습니다.
< F-Mesure 공식 >
precision 과 recall 의 조화평균

F-Mesure 를 이용해 Textboxes 모델의 Accuracy 를 구하는 방법은 다음과 같습니다.
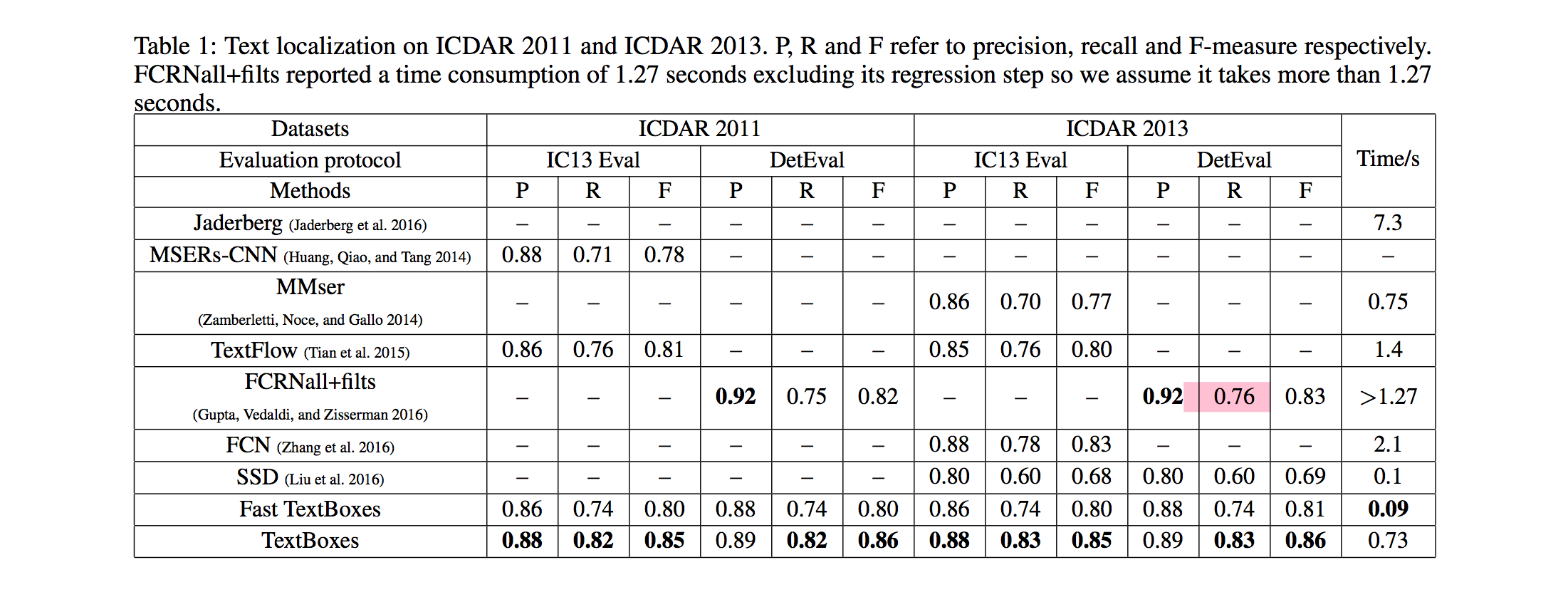
논문에서도 다양한 데이터셋에 대해 자신들이 훈련한 실제 Textboxes detection Model 의 성능을
P(Precision) / R(Recall) / F(F-Measure)
세가지 지표로 Accuracy 를 계산해 자랑해놓았습니다.
다양한 text detection 모델들과의 비교도 해놓았습니다.
논문리뷰를 마치며
실제로 Textboxes 는 C_RNN 과 같은 Recognition 모델과 연결해 한번에 학습시킬 수 있는 장점도 있습니다.
기회가 된다면 그 연결된 완성형 모델까지 리뷰해볼 생각입니다.
Textboxes 의 실제 구현도 python tensorflow 로 구현해 곧 post 로 올릴 예정이니
관심있으시면
블로그를 둘러봐주시면 감사하겠습니다.
궁금한점이나 틀린 부분은 댓글로 편하게 말씀해주시면 기쁘게 수정하겠습니다.