잠깐!
pre-requisite knowledge
아래의 지식들을 알고 계셔야 읽기 편한 글입니다.
tensorflow, numpy, matplotlib 사용법
Nueral Network (특히 Binary Classification)
epoch, batch 단위 학습 방식
이번 글에서는 GAN (Generative Adversarial Networks) 를 tensorflow code 로 구현하는 방법을 알아보려고 합니다.
간단한 GAN 알고리즘을 통해서, MNIST 숫자 손글씨 데이터와 닮은 가짜 손글씨 데이터를 만들어내는 모델(mnist_GAN)을 만들어 보겠습니다.
결과물을 미리 살짝 엿보자면 아래와 같은 실제 MNIST 데이터를
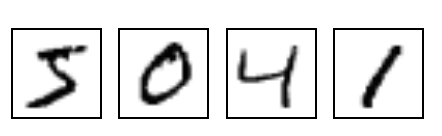
모델에게 계속 보여주면서 훈련시키면
나중에는 아래처럼 비스무리한 숫자를 스스로 만들어낼 수 있습니다.

이는 실제 제가 얻은 결과입니다.
이번 공부를 하면서 참고한 자료는 아래 링크의 코드입니다.
https://github.com/golbin/TensorFlow-Tutorials/blob/master/07%20-%20GAN/01%20-%20GAN.py
그럼 이제
어떻게 mnist 손글씨와 비슷한 이미지를 생성하는 mnist_GAN 모델을 구현하는지 보도록 하겠습니다.
01 mnist_GAN 의 구조와 데이터의 흐름
만들어볼 모델의 구조를 설명드리겠습니다.
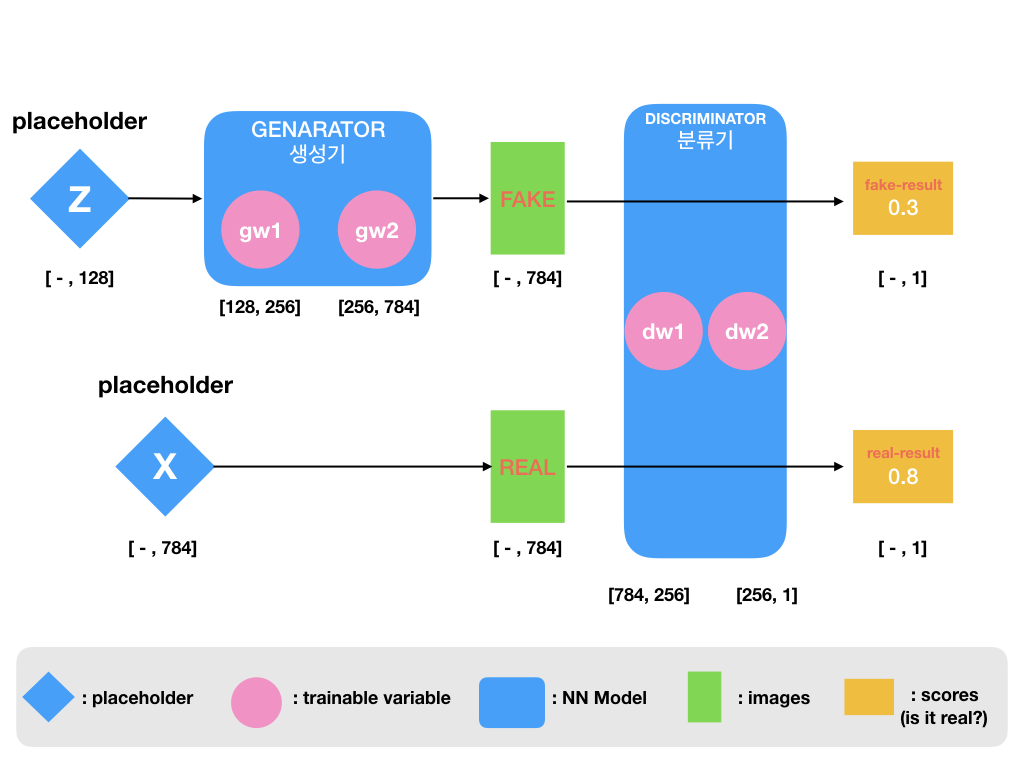
GAN 은 두개의 서로 다른 학습 가능한 모델이 서로 경쟁하면서 학습합니다.
두 모델의 이름은 각각 **Genarator(생성기) , Discriminator (분류기) **입니다 .
Discriminator (분류기)
분류기는 단순한 classification 을 수행하는 모델입니다.
이미지 데이터를 input 으로 받으면 그 이미지가 실제 이미지(real)인지 가짜 이미지(fake) 인지 분류합니다.
실제 이미지일 확률이 높으면 1에 가까운 수를,
가짜 이미지일 확률이 높으면 0에 가까운 수를 반환합니다.
분류기의 성능(성취도)는 실제 이미지를 잘 구분할수록, 즉 실제 이미지에 1에 가까운 수를 부여할수록 좋다고 할 수 있습니다.
분류기는 간단한 binary classification 기능을 할 수 있는 2 layer NN 구조를 사용했습니다.
Genarator (생성기)
생성기는 가짜 이미지를 만들어냅니다.
noise 데이터 [128] 을 input 으로 받으면, 그 noise 를 바탕으로
output 으로 만들어낸 이미지 데이터[784] 를 생성합니다.
생성기의 성능(성취도)는 자신이 만든 가짜 이미지를 분류기에 보여주었을 때 1에 가까운 수를 부여할 수록 좋다고 할 수 있습니다.
생성기 내부를 구현하는 방법에는 다양한 방법이 있을 수 있지만,
저는 단순히 2 layer NN 의 구조를 사용해보았습니다.
placeholder Z
Z 는 우리가 random 한 noise 를 넣어줄 placeholder 입니다.
미세하게 어떤 noise 가 들어갔는지에 따라서 생성기가 만들어내는 가짜이미지가 달라질 것입니다.
noise 의 크기는 임의로 128로 지정해놓았습니다.
placeholder X
X 는 분류기에게 보여줄 실제 이미지입니다.
mnist 에서 제공하는 손글씨 숫자데이터 55000개를 이용할 것입니다.
[55000, 784]
02 학습 방법 (loss function, train)
그렇다면 두개의 모델(분류기와 생성기)를 어떻게 학습시켜야할까요?
학습을 위해서는 적절한 loss function 이 필요합니다.
GAN 에는 loss function 이 손실을 나타낸다기보다 , 각 모델의 성취도 혹은 성능을 나타낸다고 하는 것이 좋을 것 같습니다.
각 모델의 loss function(성능) 을 최대화 하는 것이 학습의 목표이기 때문입니다.
위의 모델 설명에서 언급한 내용을 잠시 다시 보겠습니다.
분류기의 성능(성취도)는 실제 이미지를 잘 구분할수록, 즉 실제 이미지에 1에 가까운 수를 부여할수록 좋다고 할 수 있습니다.
생성기의 성능(성취도)는 자신이 만든 가짜 이미지를 분류기에 보여주었을 때 1에 가까운 수를 부여할 수록 좋다고 할 수 있습니다.
이 두 성취도는 위 모델 그림의 fake-result 와 real-result 로 다시 나타낼 수 있습니다.
분류기의 성능(성취도)
d_loss는 real-result 는 높을수록, fake-result 는 낮을수록 좋습니다.
생성기의 성능(성취도)
g_loss는 fake-result 가 높을수록 좋습니다.
이 d_loss 와 g_loss 를 각각 학습시켜, 최대화하도록 하면
생성기의 성능과 분류기의 성능이 서로 경쟁적으로 올라가게 됩니다.
03 학습을 마친 후에는 …
생성기에 새로운 noise 를 넣어서 실제 손글씨와 비슷한 이미지를 만들어내는지 확인해볼 것입니다.
04 Tensorflow Code 로 직접 짜보기
이제 개념 정리와 어떻게 모델을 구성하고 학습할지에 대한 계획이 끝났으니,
실제 tensorflow 로 코드를 짜보도록 하겠습니다.
(1) Import Packages
(2) 사용할 데이터 load
(3) Hyper-Parameters 설정
(4) 필요한 module 만들기
(5) Graph 짜기
(6) Graph Run 해서 반복 training 으로 variable update
(1) Import Packages
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
(2) 사용할 데이터 load
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/")
Extracting MNIST_data/train-images-idx3-ubyte.gz
Extracting MNIST_data/train-labels-idx1-ubyte.gz
Extracting MNIST_data/t10k-images-idx3-ubyte.gz
Extracting MNIST_data/t10k-labels-idx1-ubyte.gz
train_x = mnist.train.images
train_y = mnist.train.labels
print(train_x.shape, train_y.shape)
(55000, 784) (55000,)
(3) Hyper-Parameters 설정
total_epochs = 100
batch_size = 100
learning_rate = 0.0002
(4) 필요한 module 만들기
| 모듈이름 | 기능 | input | output | trainable_variables |
|---|---|---|---|---|
| generator | 2 layer NN 로 구성된 가짜이미지 생성기를 호출합니다. | noise z [-, 128] | fake images [-,784] | Gen/w1, Gen/b1, Gen/w2, Gen/gb2 |
| discriminator | 2 layer NN 로 구성된 binary 분류기를 호출합니다. | real/fake images x [-,784] | scores [-,1] | Dis/w1, Dis/b1, Dis/w2, Dis/b2 |
| random_noise | 호출할 때마다 random normal한 batch_size 갯수의 noise 를 생성합니다. | batch_size | noise [batch_size, 128] | - |
< module1 : Generator ( 생성기 ) >
def generator( z , reuse = False ) :
if reuse==False :
with tf.variable_scope(name_or_scope = "Gen") as scope :
gw1 = tf.get_variable(name = "w1",
shape = [128, 256],
initializer= tf.random_normal_initializer(mean=0.0, stddev = 0.01))
# quiz : weight 의 초깃값을 random normal 로 주는 이유는 무엇일까요?
gb1 = tf.get_variable(name = "b1",
shape = [256],
initializer = tf.random_normal_initializer(mean=0.0, stddev = 0.01))
gw2 = tf.get_variable(name = "w2",
shape = [256, 784],
initializer= tf.random_normal_initializer(mean=0.0, stddev = 0.01))
gb2 = tf.get_variable(name = "b2",
shape = [784],
initializer = tf.random_normal_initializer(mean=0.0, stddev = 0.01))
else :
with tf.variable_scope(name_or_scope="Gen", reuse = True) as scope :
gw1 = tf.get_variable(name = "w1",
shape = [128, 256],
initializer= tf.random_normal_initializer(mean=0.0, stddev = 0.01))
gb1 = tf.get_variable(name = "b1",
shape = [256],
initializer = tf.random_normal_initializer(mean=0.0, stddev = 0.01))
gw2 = tf.get_variable(name = "w2",
shape = [256, 784],
initializer= tf.random_normal_initializer(mean=0.0, stddev = 0.01))
gb2 = tf.get_variable(name = "b2",
shape = [784],
initializer = tf.random_normal_initializer(mean=0.0, stddev = 0.01))
hidden = tf.nn.relu( tf.matmul(z , gw1) + gb1 )
output = tf.nn.sigmoid( tf.matmul(hidden, gw2) + gb2 ) #출력층에 시그모이드를 쓰는 이유는 무엇일까요?
return output #[784] 가짜 생성된 이미지
< module2 : Discriminator ( 분류기 ) >
def discriminator( x , reuse = False) :
if(reuse == False) :
with tf.variable_scope(name_or_scope="Dis") as scope :
dw1 = tf.get_variable(name = "w1",
shape = [784, 256],
initializer = tf.random_normal_initializer(0.0, 0.01) )
db1 = tf.get_variable(name = "b1",
shape = [256],
initializer = tf.random_normal_initializer(0.0, 0.01) )
dw2 = tf.get_variable(name = "w2",
shape = [256, 1],
initializer = tf.random_normal_initializer(0.0, 0.01) )
db2 = tf.get_variable(name = "b2",
shape = [1],
initializer = tf.random_normal_initializer(0.0, 0.01) )
else :
with tf.variable_scope(name_or_scope="Dis", reuse = True) as scope :
dw1 = tf.get_variable(name = "w1",
shape = [784, 256],
initializer = tf.random_normal_initializer(0.0, 0.01) )
db1 = tf.get_variable(name = "b1",
shape = [256],
initializer = tf.random_normal_initializer(0.0, 0.01) )
dw2 = tf.get_variable(name = "w2",
shape = [256, 1],
initializer = tf.random_normal_initializer(0.0, 0.01) )
db2 = tf.get_variable(name = "b2",
shape = [1],
initializer = tf.random_normal_initializer(0.0, 0.01) )
hidden = tf.nn.relu( tf.matmul(x , dw1) + db1 ) #[-, 256]
output = tf.nn.sigmoid( tf.matmul(hidden, dw2) + db2 ) #[-, 1] 진품인지(1) 가품인지(0)의 label 결과값
return output
< module3 : random noise 생성기 >
def random_noise(batch_size) :
return np.random.normal(size=[batch_size , 128])
(5) Graph 짜기
g = tf.Graph()
with g.as_default() :
######################################################
# 1 .Feedable part :: 그래프에서 유일하게 데이터가 유입될 수 있는 장소
######################################################
X = tf.placeholder(tf.float32, [None, 784]) #GAN 은 autoencoder 와 마찬가지로 unsupervised learning 이므로 y(label)을 사용하지 않습니다.
Z = tf.placeholder(tf.float32, [None, 128]) #Z 는 생성기의 입력값으로 사용될 노이즈 입니다.
################################
# 2. generator 와 discriminator 의 사용
##################################
fake_x = generator(Z)
result_of_fake = discriminator(fake_x)
result_of_real = discriminator(X , True)
################################
# 3. Loss( 성취도평가 ) : g_loss 와 d_loss
# g_loss & d_loss 모두 높을 수록 좋다.
# g_loss : 얼마나 fake_x 가 진짜같은가
# d_loss : 얼마나 discriminator 가 정확한가
# 두 수치를 모두 높이도록 train 하면 생성기와 분류기의 성능이 모두 올라간다.
################################
g_loss = tf.reduce_mean( tf.log(result_of_fake) )
d_loss = tf.reduce_mean( tf.log(result_of_real) + tf.log(1 - result_of_fake) )
################################
# 4. Train : Maximizing g_loss & d_loss
################################
t_vars = tf.trainable_variables() # return list
g_vars = [var for var in t_vars if "Gen" in var.name]
d_vars = [var for var in t_vars if "Dis" in var.name]
optimizer = tf.train.AdamOptimizer(learning_rate)
g_train = optimizer.minimize(-g_loss, var_list= g_vars)
d_train = optimizer.minimize(-d_loss, var_list = d_vars)
# g_loss & d_loss 를 최대화 시켜야하는데 minimize 함수밖에 없기 때문에 - 음수부호 붙인다.
(6) Graph Run 해서 반복 training 으로 variable update
with tf.Session(graph = g) as sess :
sess.run(tf.global_variables_initializer())
total_batchs = int(train_x.shape[0] / batch_size)
for epoch in range(total_epochs) :
for batch in range(total_batchs) :
batch_x = train_x[batch * batch_size : (batch+1) * batch_size] # [batch_size , 784]
batch_y = train_y[batch * batch_size : (batch+1) * batch_size] # [batch_size,]
noise = random_noise(batch_size) # [batch_size, 128]
sess.run(g_train , feed_dict = {Z : noise})
sess.run(d_train, feed_dict = {X : batch_x , Z : noise})
gl, dl = sess.run([g_loss, d_loss], feed_dict = {X : batch_x , Z : noise})
#매 20 epoch 마다 학습된 성능을 중간점검 (실제론 더 자주하시는 것이 좋습니다. )
if (epoch+1) % 20 == 0 or epoch == 1 :
print("=======Epoch : ", epoch , " =======================================")
print("생성기 성능 : " ,gl )
print("분류기 성능 : " ,dl )
print("생성기와 분류기 선의의 경쟁중...")
#10개의 epoch 마다 Generator 가 만들어내는 실제 결과물을 얻어보며 , 성능 발전을 시각적으로 확인
if epoch == 0 or (epoch + 1) % 10 == 0 :
sample_noise = random_noise(10)
generated = sess.run(fake_x , feed_dict = { Z : sample_noise})
fig, ax = plt.subplots(1, 10, figsize=(10, 1))
for i in range(10) :
ax[i].set_axis_off()
ax[i].imshow( np.reshape( generated[i], (28, 28)) )
plt.savefig('goblin-gan-generated/{}.png'.format(str(epoch).zfill(3)), bbox_inches='tight')
plt.close(fig)
print('최적화 완료!')
=======Epoch : 1 =======================================
생성기 성능 : -3.06128
분류기 성능 : -0.200115
생성기와 분류기 선의의 경쟁중...
=======Epoch : 19 =======================================
생성기 성능 : -2.32224
분류기 성능 : -0.4686
생성기와 분류기 선의의 경쟁중...
=======Epoch : 39 =======================================
생성기 성능 : -1.91436
분류기 성능 : -0.619524
생성기와 분류기 선의의 경쟁중...
=======Epoch : 59 =======================================
생성기 성능 : -1.69127
분류기 성능 : -0.593143
생성기와 분류기 선의의 경쟁중...
=======Epoch : 79 =======================================
생성기 성능 : -1.62559
분류기 성능 : -0.574774
생성기와 분류기 선의의 경쟁중...
=======Epoch : 99 =======================================
생성기 성능 : -1.76843
분류기 성능 : -0.501177
생성기와 분류기 선의의 경쟁중...
최적화 완료!
05 결과물 보기
위의 코드에서 , 매 10 epoch 마다 generator(생성기) 에 임의의 noise 10개를 주어서 생성되는 10개의 이미지를 저장했습니다.
이 결과를 보면 , 학습이 진행되면 진행될수록 생성기가 실제 사람 손글씨와 비슷한 이미지 형태를 생성해냄을 볼 수 있습니다.
epoch 0

epoch 9

epoch 19

epoch 29

epoch 39

epoch 49

epoch 59

epoch 69
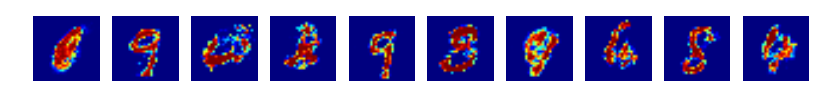
epoch 79

epoch 89

epoch 99
마치며 …
간단한 2 layer NN 와 mnist data, 그리고 GAN 구조를 이용해 mnist 손글씨를 흉내내는 모델을 tensorflow 만들어보았습니다.
코드를 보시다 궁금한 점이나 오류가 있다면
아래 댓글로 남겨주시면 감사하겠습니다 ^^ .