open-AI 에서 파이썬 패키지로 제공하는 gym 을 이용하면 , 손쉽게 강화학습 환경을 구성할 수 있다.
gym package 를 이용해서 강화학습 훈련 환경을 만들어보고, Q-learning 이라는 강화학습 알고리즘에 대해 알아보고 적용시켜보자.
목차
3. 완벽한 Q-learning ( Dummy Q-learning 의 문제 )
1. gym package 이용하기
open-AI 에서 만든 gym 이란 파이썬 패키지를 이용하면 강화학습( Reinforcement Learning ) 훈련을 수행할 수 있는 Agent와 Environment 를 제공받을 수 있다.
gym 을 간단하게 pip install 통해서 설치할 수 있다.
# command line (bash)
$ pip install gym
$ pip install readchar
실제로 gym 을 사용해본다.
# gym_example.py
import gym
from gym.envs.registration import register
import readchar
LEFT = 0
DOWN = 1
RIGHT = 2
UP = 3
arrow_keys = {
'\x1b[A' : UP,
'\x1b[B' : DOWN,
'\x1b[C' : RIGHT,
'\x1b[D' : LEFT
}
register(
id='FrozenLake-v3',
entry_point="gym.envs.toy_text:FrozenLakeEnv",
kwargs={'map_name':'4x4','is_slippery':False})
'''여기서부터 gym 코드의 시작이다. env 는 agent 가 활동할 수 있는 environment 이다.'''
env = gym.make("FrozenLake-v3")
env.render() #환경을 화면으로 출력
while True:
key = readchar.readkey() #키보드 입력을 받는다
if key not in arrow_keys.keys():
print("Game aborted!")
break
action = arrow_keys[key] #에이젼트의 움직임
state, reward, done, info = env.step(action) #움직임에 따른 결과값들
env.render() #화면을 다시 출력
print("State:", state, "Action", action, "Reward:", reward, "Info:", info)
if done: #도착하면 게임을 끝낸다.
print("Finished with reward", reward)
break
위와 같은 코드로, 내가 직접 게임을 진행해볼 수 있다.
2. Q-learning 이란?
위의 gym-example.py 코드같은 environment 에서, agent 가 무작위로 방향을 결정하면 학습이 잘 되지 않는다.
시도 횟수는 엄청 많은데에 비해 reward는 성공할 때 한번만 지급되기 때문이다.
그에 대한 해결책이 바로 Q-learning 이다.
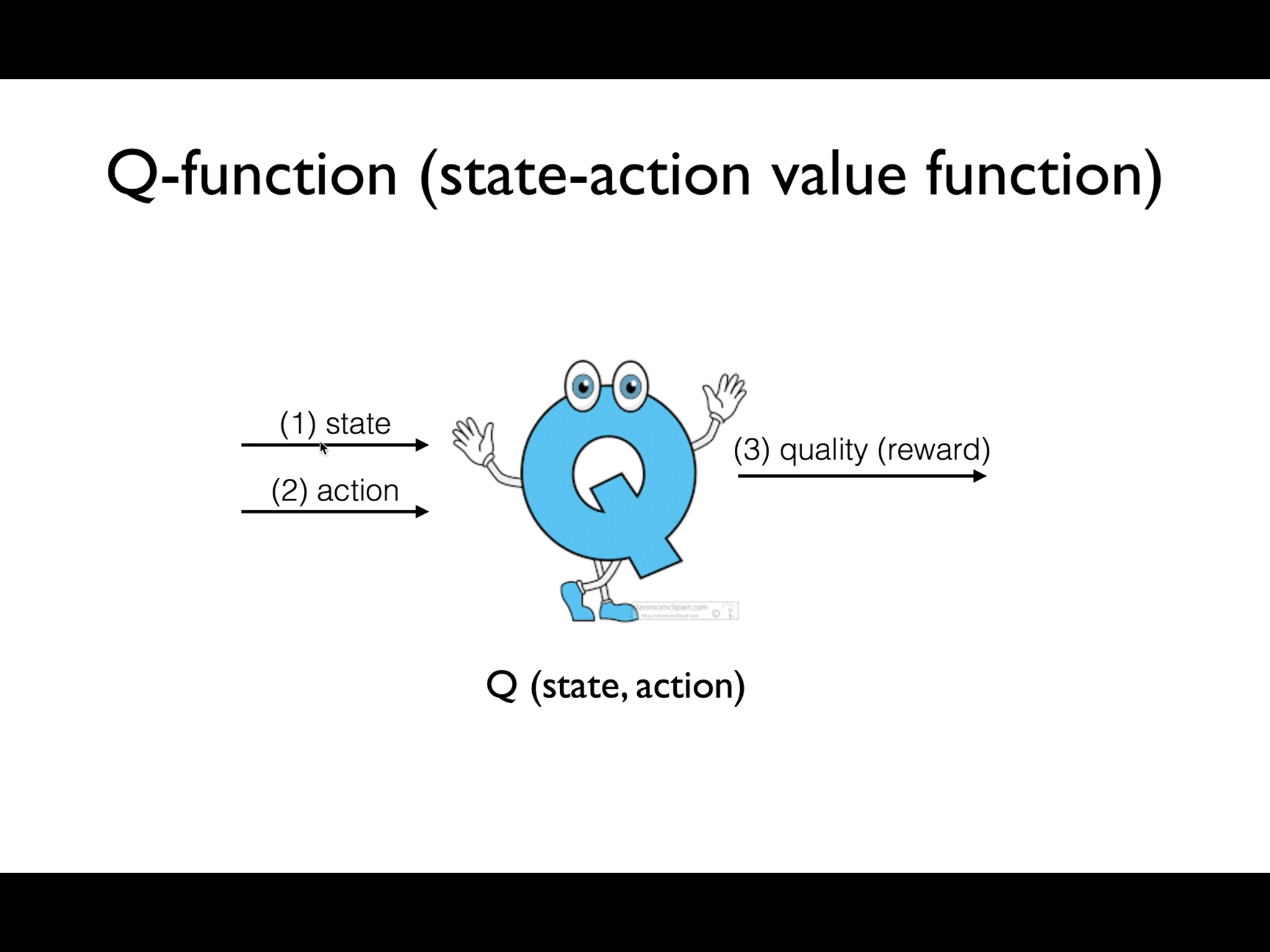
agent는 방향을 결정해야할 때마다 가상의 Q 에게 행보를 물어본다.
Q 는 agent 의 state를 보고 그가 action1 을 취하면 기대되는 reward1(quality1) 을 알려주고, action2 를 취하면 기대되는 reward2(quality2) 를 알려준다.
agent 는 Q의 도움을 받아 더 빠른 학습이 가능하다.
수식적으로는
Q(s, a) = π 처럼 쓸 수 있으며
현재 s(state)에서 취할수 있는 가장 큰 reward 인 max Q max(Q(s,a)) 로
현재 s(state)에서 max(Q(s,a))로 가게 해주는 action 은 argmax(Q(s,a)) 로 표현한다.
argmax(Q(s,a))는 π*(s) 로도 표현하며 여기서 *은 optimal 함을 의미한다.

Q-learning 의 학습 (Greedy, Dummy)
Q-learning 알고리즘에서 학습한다는 것은 아래 그림처럼 모두 0으로 초기화되어있는 모든 Q 값들을 하나씩 업데이트시킨다는 것과 같다.
모든 칸의 0은 각각의 Q(s,a) 값을 나타낸다.
도착지점으로 넘어갈 때에만 reward = 1 이 주어지고, 나머지 부분으로 넘어갈 때에는 reward = 0 이다.

우선 각 칸의 Q 값을 업데이트 하는 방법은 다음과같다.
Q(s,a) 의 값은 (다음칸의 Q 중 가장 큰 값 + reward) 로 표현해서 적는다.

처음에는 어디로 가든 reward 도 0이고 max Q(s’, a’) 도 0이다. 그래서 agent가 무작위로 방향을 결정한다. 그러다 우연히 아래 그림처럼 도착지점 바로 왼쪽칸에 도착했다.
이때 Q(s14, right) 의 값은 reward = 1 값 더하기 maxQ(s15,a’) = 0 으로 1 로 업데이트된다.
이게 첫번째 학습이다.

한번 학습이 끝난 후 agent 는 다시 시작지점에서 출발한다. 역시나 대부분의 Q가 0으로 초기화되어있고, 주변의 reward 도 0이기 때문에 무작위로 나아간다.
그러다 다시 우연히 s13 칸에 도착했다고 하자.
이때 Q(s13,right) 를 계산해보았더니, reward = 0 이지만 max Q(s’,a’) 이 1이다.
이렇게 다시 Q(s13,right) = 1 로 업데이트하고 다시 agent 를 시작점으로 보낸다.
이런식으로 계속해서 학습을 하다보면 결국 아래 그림처럼 시작 지점의 Q 까지 학습이 되고, 이렇게 Dummy Q-learning 의 학습이 끝난다.

루틴을 정리하자면 다음과 같다.

Dummy Q-learning 학습 - python code
# dummy_q_learning.py
import gym
import numpy as np
import matplotlib.pyplot as plt
from gym.envs.registration import register
import random as pr
def qmax_action(four_q):
""" 상태 s 에서 네가지 a 에 따른 네가지 Q 중 가장 큰 것을 선택 (같으면 랜덤하게 선택)"""
maxq = np.amax(four_q)
indices = np.nonzero(four_q == maxq)[0]
return pr.choice(indices)
register(
id='FrozenLake-v3',
entry_point='gym.envs.toy_text:FrozenLakeEnv',
kwargs={'map_name': '4x4',
'is_slippery': False}
)
env = gym.make('FrozenLake-v3')
# shape = [States num, 4(left,down,right,up)]
Q = np.zeros([env.observation_space.n, env.action_space.n])
# Set learning parameters
num_episodes = 2000
# create lists to contain total rewards and steps per episode
rList = []
for i in range(num_episodes):
# Reset environment and get first new observation
state = env.reset()
rAll = 0
done = False
# The Q-Table learning algorithm
while not done:
action = qmax_action(Q[state, :])
# Get new state and reward from environment
new_state, reward, done, _ = env.step(action)
# Update Q-Table with new knowledge using learning rate
Q[state, action] = reward + np.max(Q[new_state, :])
rAll += reward
state = new_state
rList.append(rAll)
print("Success rate: " + str(sum(rList) / num_episodes))
print("Final Q-Table Values")
print("LEFT DOWN RIGHT UP")
print(Q)
plt.bar(range(len(rList)), rList, color="blue")
plt.show()
3. 완벽한 Q-learning ( Dummy Q-learning 의 문제 )
dummy Q-learning 의 문제는 아래 그림처럼 가장 optimal 한 경로를 따라 Q 가 업데이트 되지 않을 수 있는 가능성이 있다는 것이다.

해결할 수 있는 방법은 단 하나다.
가끔은 최적의 Q로 이동하는 action 이 아닌 랜덤한 action을 취해주는 것이다.
(예를들어 위 그림에서 첫번째 state 일때, 오른쪽으로 가지 않고 한번 아래로 가보는 action을 취해보는 것이다.)
그 방법으로 2가지가 있다.
E-greedy (랜덤한 확률로 아무데나 가본다.)
add Random noise (Q 에 random noise 를 더해 랜덤한 action 을 취한다.)
위 두가지에 대해 자세히 알아보자.
해결책 1 : E-greedy

일정 확률로 가끔은 최적의 action 을 따라가지 않도록 설정한다.
해결책 2 : add Random noise

action 을 결정할 때 참고하는 각 Q 값에 random 한 noise 를 주어서 action 이 조금 random 해지도록 한다.
새로운 문제 : 여러 경로가 생긴다
위와 같이 dummy Q learning 문제를 보완하는 기법들을 사용하면 agent 가 최종적으로 경로를 결정하려고 할 때 선택의 문제에 놓인다.

이런 상황을 막으려면 학습과정에서 Q를 업데이트할 때, 다음 max Q(s’, a’) 값에다 특정 감마(<1) 값을 곱해준다.
그러면 상대적으로 구불하고 긴 경로로 인도하는 Q 값들은 작아지고, 가장 짧은 경로로 인도하는 Q 값들은 커진다.

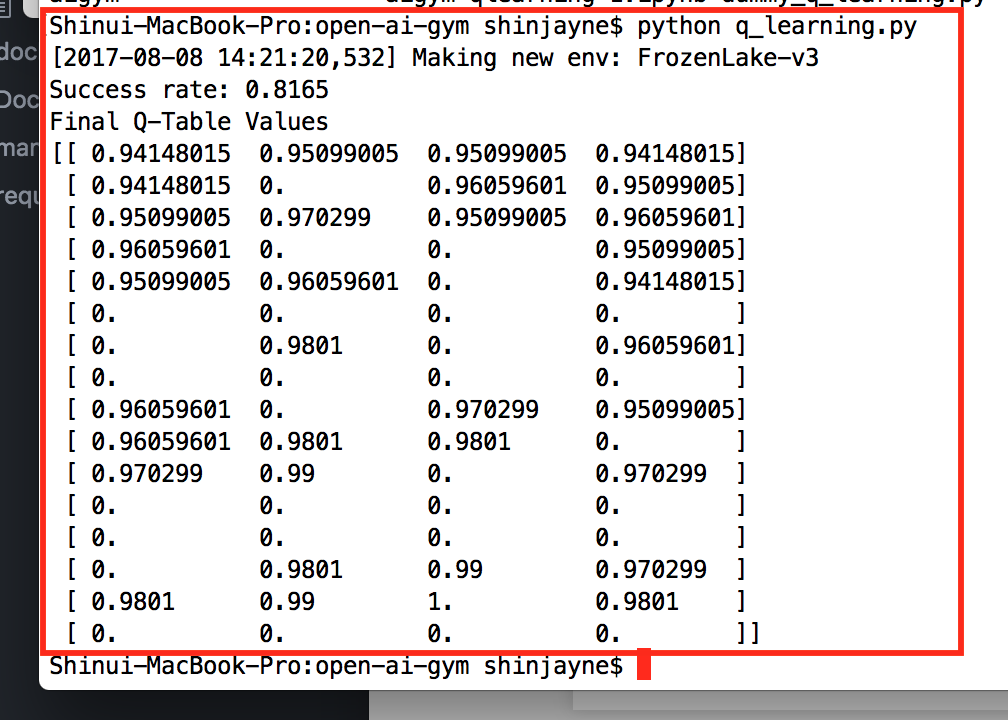
Q-learning python 코드와 실행결과
# q_learning.py
import gym
import numpy as np
import matplotlib.pyplot as plt
from gym.envs.registration import register
import random as pr
register(
id='FrozenLake-v3',
entry_point='gym.envs.toy_text:FrozenLakeEnv',
kwargs={'map_name': '4x4',
'is_slippery': False}
)
env = gym.make('FrozenLake-v3')
# Initialize table with all zeros
Q = np.zeros([env.observation_space.n, env.action_space.n])
'''1. Q 값이 업데이트될 때 maxQ(s',a') 에 곱할 감마 값을 설정한다.'''
dis = .99
num_episodes = 2000
# create lists to contain total rewards and steps per episode
rList = []
for i in range(num_episodes):
# Reset environment and get first new observation
state = env.reset()
rAll = 0
done = False
'''2. E-Greedy 를 위한 확률값을 만들어준다. (step i이 지남에 따라 decay 되도록 설정)'''
e = 1. / ((i // 100) + 1)
# The Q-Table learning algorithm : 한번 수행할 때 마다 Q 한칸 업데이트
while not done:
'''E-Greedy 를 따라 작은 확률로 랜덤하게 가고, 큰 확률로 높은 Q 를 따르는 쪽으로 간다.'''
if np.random.rand(1) < e:
action = env.action_space.sample()
else:
action = np.argmax(Q[state, :])
# Get new state and reward from environment
new_state, reward, done, _ = env.step(action)
# Update Q-Table with new knowledge using learning rate
Q[state, action] = reward + dis * np.max(Q[new_state, :])
rAll += reward
state = new_state
rList.append(rAll)
print("Success rate: " + str(sum(rList) / num_episodes))
print("Final Q-Table Values")
print(Q)
plt.bar(range(len(rList)), rList, color="blue")
plt.show()